
Join cardinality setting in Calculation Views: Influence of join cardinality on pruning decisions
Manually set the cardinality of the previous view developed here to “1..1” and route through all fields so you can build the view.
Make sure that field “employee_1” is indeed coming from the left table. If this is not the case (e.g., because you build the model in a slightly different way) change the column mapping in the join node so that “employee_1” refers only to the left table.
After the view has been successfully build debug the view by pressing the button highlighted below:

Start debugging by selecting node “Semantics” and pressing the debug button.
Exchange the default debug query with a query that only requests fields from the left table and run the query (you probably will need to adapt the view name):
SELECT
“salesOrder”,
“employee_1”,
SUM(“amount”) AS “amount”
FROM
“JOINCARDINALITY_1″.”joinCardinalityExample.db.CVs::JoinNoEstimateCardinality”
GROUP BY
“salesOrder”,
“employee_1”
The executed debug query shows the pruned nodes and fields in grey:

Pruned nodes and fields are indicated by grey texts
Based on the greyed-out objects you can conclude that indeed “employees” was pruned away.
Pruning was possible because
a) no field was requested from employees (“employee_1” comes from the left table),
b) only left-outer joins are involved so that no records could be removed by executing the join, and
c) the cardinality was set so that no increase in number of records would be expected by executing the join.
If you included fields from the right table (e.g., field “manager”) join pruning would not occur because the join has to be executed to associate the records from both tables. You could test this with the following debug query that requests field “manager” from the right table in addition:
SELECT
“salesOrder”,
“employee_1”,
“manager”,
SUM(“amount”) AS “amount”
FROM
“JOINCARDINALITY_1″.”joinCardinalityExample.db.CVs::JoinNoEstimateCardinality”
GROUP BY
“salesOrder”,
“employee_1”,
“manager”

Current debug prevents pruning
Looking at the result of running the debug query shows that “employees” is not greyed out meaning that it was not pruned.
As further demonstrations of the impact of the cardinality setting on join pruning: Set sequentially cardinality to the following values:
– “n..1”
– “1..n”
– leave it empty
Don’t forget to save and build the Calculation View before running the debug query that only goes to the left table:
SELECT
“salesOrder”,
“employee_1”,
SUM(“amount”) AS “amount”
FROM
“JOINCARDINALITY_1″.”joinCardinalityExample.db.CVs::JoinNoEstimateCardinality”
GROUP BY
“salesOrder”,
“employee_1”
You will see that pruning only occurs with left-outer join and “n..1” (or “1..1” from before). As discussed above, inner joins will prevent pruning.
Analogously, for right-outer joins only “1..1” and “1..n” work. To check this swap the join sides by pressing the button highlighted below:

Button to swap left and right tables
and define a right outer join with cardinality “1..n”:

Definition of a right outer join
Join pruning will occur. As debug query you could for example use:
SELECT
“employee_1”,
SUM(“amount”) AS “amount”
FROM
“JOINCARDINALITY_1″.”joinCardinalityExample.db.CVs::JoinManualCardinalityRightOuter”
GROUP BY
“employee_1”
One final example in this section will show the influence of the type of requested measures: In the examples before join pruning only worked when there was an outer-join setting and the to-be-pruned table had a cardinality of “..1”.
If you only request a count distinct measure in this example also a cardinalty of “n..m” will allow pruning to occur. The reason is that count distinct will remove any potential duplicates and the outer join will gurantee that no records are lost. In sum, as no records can be lost due to the outer join and potential duplicate records do not influence the outcome of count distinct measures, executing the join does not influence the value of the measure. Therefore, the join can be omitted if no fields are requested from the to-be-pruned table. What holds for count distinct measures also holds if no measures are requested by the query: Obviously, if no measures are requested by the query also no impact of joining on the non-requested measures is expected and join pruning can occur.
To see this working, define a calculated column as a count distinct on field “employee_1”:
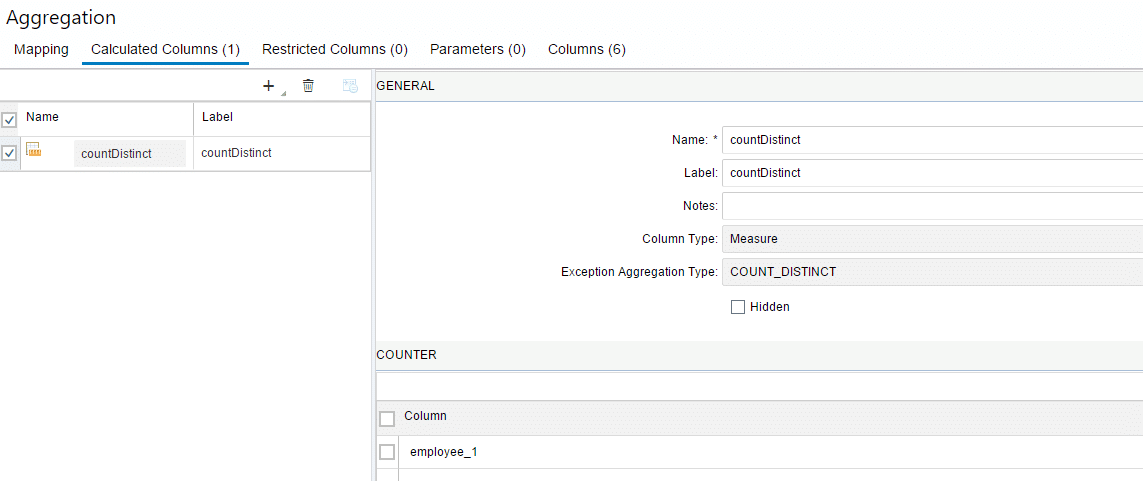
Definition of a calculated column of type count distinct
Set the cardinality to “n..m”:

Definition of cardinality “n..m
Debug queries, that only request the count distinct measure and fields from the left table will show table pruning. For example,
SELECT
“employee_1”,
SUM(“countDistinct”) AS “countDistinct”
FROM
“JOINCARDINALITY_1″.”joinCardinalityExample.db.CVs::JoinEstimateCardinalityCountDistinct”
GROUP BY
“employee_1”
Instead of running again in debug view let’s use a different way to check whether join pruning occurs: Go to Database Explorer by clicking the icon on the left,

Button to start Database Explorer
open a SQL console where you enter the debug query and right-click on it to run “Analyze SQL”:

Start Analyze SQL
You will see that only one table was used:

Only one table was used while processing current query
This demonstrates that join pruning occurs also with a cardinality setting of “n..m” when only a count distinct measure is used. If you add the additional measure “amount” to the query you will see that two tables are involved. This can also be checked by EXPLAIN PLAN which currently does not run in Database Explorer though:
EXPLAIN PLAN FOR
SELECT
“employee_1”,
SUM(“countDistinct”) AS “countDistinct”,
SUM(“amount”) AS “amount”
FROM
“JOINCARDINALITY_1″.”joinCardinalityExample.db.CVs::JoinEstimateCardinalityCountDistinct”
GROUP BY
“employee_1”

Output of Explain Plan
As you can see no join pruning occurs and both tables are used.
If you are unsure about the authorizations needed to run EXPLAIN PLAN in SAP HANA Studio on HDI-container objects and you are in a test environment you could simply add the access_role of your container (JOINCARDINALITY_1 in the current example) to your Studio user. The downside of this quick and dirty approach is that it assigns too many additional privileges that are contained in the role. Assigning too many privileges is something you probably want to avoid in a real scenario.
New NetWeaver Information at SAP.com
Very Helpfull